特征工程
在机器学习任务中,特征工程是最繁琐最耗时的。有人认为特征决定了结果的上限,而模型则是去逼近这个上限。文本分类任务中,特征工程通常包括文本预处理、文本表达、特征提取。
文本预处理
文本预处理通常包括去标点、停顿词 (stop words)。当然具体应用场景应该具体分析,比如英文分词考虑统一各时态的表达,包含外文词汇时翻译成目标语言,对特殊的词做正则(比如在 Toxic Comment Classification Challenge 比赛中对 fuuuuck 这样的词做特殊匹配),有时甚至不需要去除停顿词(比如 you, my 等词在谩骂时经常出现)。介绍几个 Python 文本预处理的库:torchtext, nltk。
文本表达
文本分类问题多采用词的粒度的特征,所以这里主要讲词的表达。常见的表达方式有:
- one-hot representation: 例如词袋模型(BOW, Bag Of Words),就采用这种稀疏表达。缺点是向量维度随词的增多可能爆炸,并且每个词都是独立的,难以表达语义信息。
- distributed representation: 例如词嵌入(Word Embeddings),采用这种稠密表达。它基于上下文,包含更丰富的语义信息。常见的模型有GloVe, word2vec。在实践中可能还会使用 char embedding, n-gram embedding。
特征提取
传统的特征提取通常包括特征选择和权重计算。权重计算通常用TF-IDF及其变体,主要思路是:字词的重要性随着它在文本中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
而深度神经网络解决了自动特征提取。
其他 trick
实际的特征工程中还有许多有用的方法,比如数据增强 (Data Augmentation)。这里介绍一些文本分类中数据增强的方法:
- 加噪声。如删减一些词,打乱词序,分隔合成词 (split combined words)。
- 翻译成其他语言再翻译回来。Kaggle 上关于这个方法的讨论:A simple technique for extending dataset
- 伪标签 (pseudo-labelling)。在训练集和测试集数据分布不一致时,这种方法尤为有效。它的运行过程如下图:
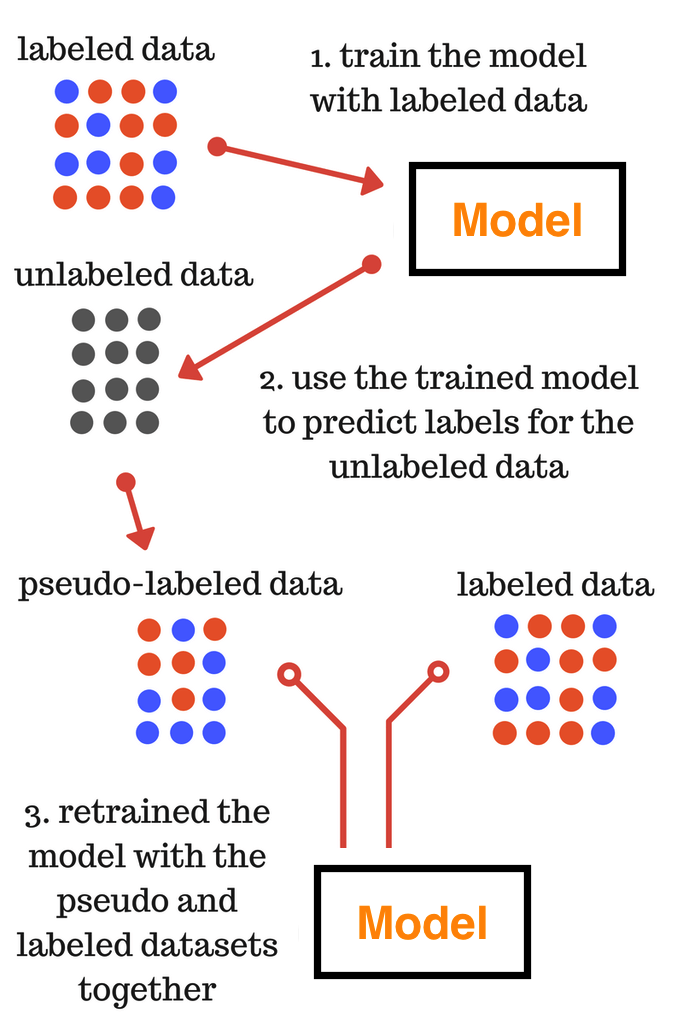
一篇介绍它的论文:Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks - 拼接词汇:把一些词拼接成一个短文本进行训练,如在 Mercari Price Suggestion Challenge 中把名称和品牌 concat 成一个短文本。
- label embedding:在多任务学习中使用 label embedding,提取标签的语义信息,利于迁移学习。详情见论文Multi-Task Label Embedding for Text Classification
文本分类模型
常见模型
- fastText
- TextCNN
- TextRNN
- TextRCNN
- Hierarchical Attention Network
- seq2seq with attention
- Transformer (Attention Is All You Need)
- Dynamic Memory Network
模型细节
fastText
fastText 并不是用深度学习解决文本分类的主流方法,但是它非常简单,而且特别快。Bag of Tricks for Efficient Text Classification。模型如下图: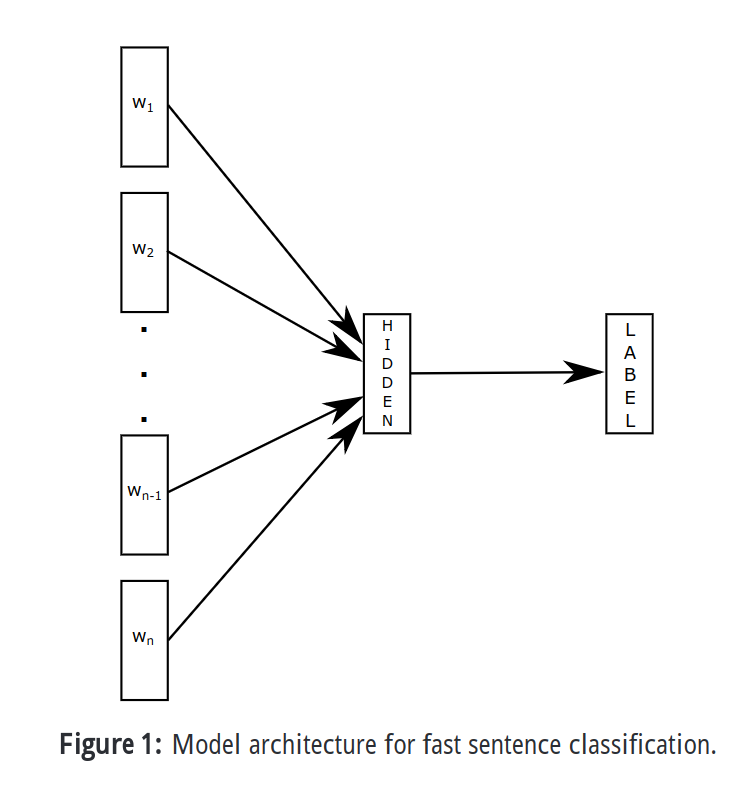
原理是把句子的词向量做了平均然后接一个线性分类器,文中使用 softmax 来计算概率。为了加速训练,文中还用了层次化 softmax (Hierarchical softmax),这是一种基于Huffman树的结构,详情见论文。文中还加入了一些 n-gram 特征来捕获关于词序的局部特征。值得一提的是,它的训练速度极快,即使用 CPU 训练,通常也比 CNN 方法快很多倍。Facebook 开源了这个库 fastText
TextCNN
原文链接:Convolutional Neural Networks for Sentence Classification,还有一篇关于它的 Guide: A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
原理见下图:
原文的配置如下:
| Description | Values |
|---|---|
| input word vectors | Google word2vec |
| feature maps | 100 |
| activation function | ReLU |
| pooling | 1-max pooling |
| dropout rate | 0.5 |
| l2 norm constraint | 3 |
文中的词向量有 static 和 non-static 两种,即一种直接使用预训练的词向量,一种在训练网络的过程中同时调整词向量。使用单 filter 准确率高的 filter 组合能获得更好的效果。Github 上有许多实现可以参考:cnn-text-classification-pytorch, text-cnn-tensorflow
还有一些文章使用 k-max pooling,如A Convolutional Neural Network for Modelling Sentences,即保留 k 个最大值。它可以保留局部信息。在实践中通常加入 attention,可参考 ABCNN。
TextRNN
TextRNN 的原理可以参考:Recurrent Neural Network for Text Classification with Multi-Task Learning
文中把 word embedding 输入给双向 LSTM 后直把 $h_T$ 输给 FC 然后 softmax 输出,使用 Adagrad 训练,Loss 为交叉熵。
TextRCNN
原文链接:Recurrent Convolutional Neural Networks for Text Classification
这篇文章用单词本身和上下文了来表示一个词。它的原理如下图: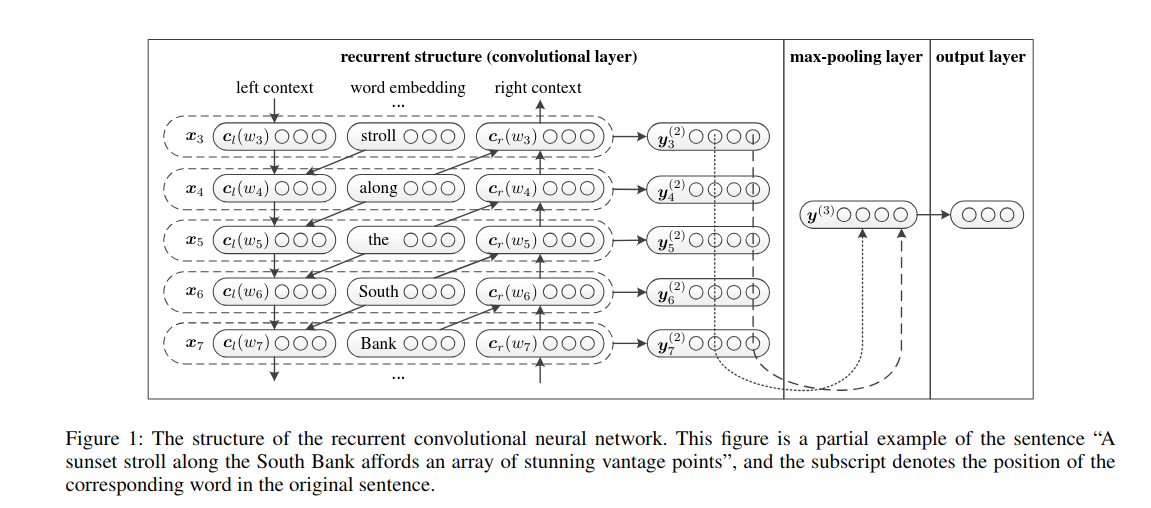
它使用双向 RNN 来获取一个词的上下文,其中:
$$c_l(w_i) = f(W^{(l)}c_l(w_{l-1}) + W^{(sl)}e(w_{i-1})))$$ $$c_r(w_i) = f(W^{(r)}c_r(w_{r+1}) + W^{(sr)}e(w_{i+1})))$$
然后把它们 concat 起来得到词的表示:$$x_i = [c_l(w_i);e(w_i);c_r(w_i)]$$
再通过$y_i^{(2)} = tanh(W^{(2)}x_i + b^{(2)})$ 得到 $y_i^{(2)}$,它是潜在的语义向量。再接 max-pooling,最后 FC + softmax 输出。从卷积神经网络的角度看,前面提到的循环结构相当于卷积层。在训练时最大化它的极大似然函数,并且用 SGD 优化。
Hierarchical Attention Network
原文链接:Hierarchical Attention Networks for Document Classification
本文在 attention 机制的基础上提出了层次化的结构,即由词向量得到句子向量,由句子向量得到文档向量,并在层间加入 attention。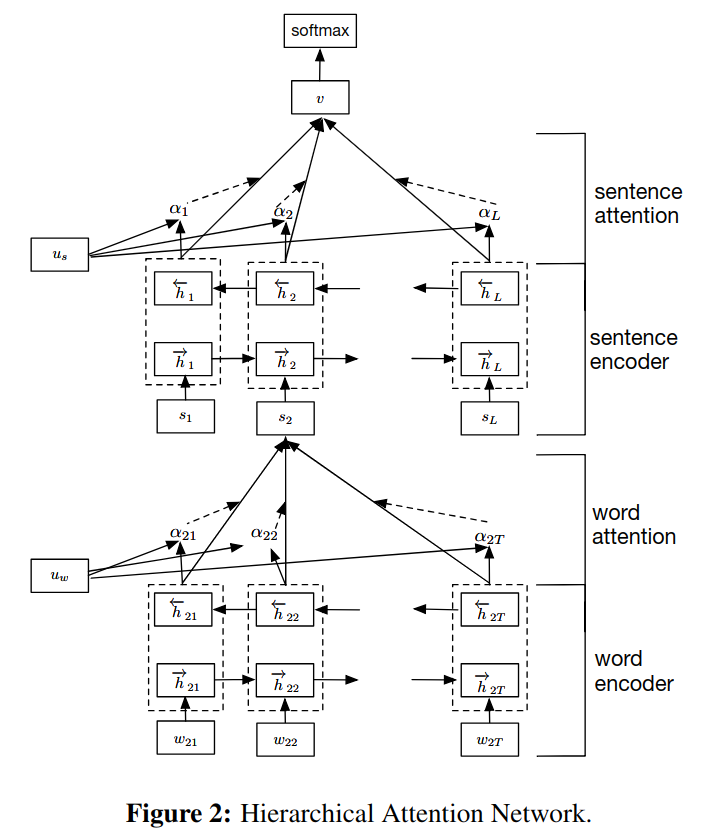
本文使用基于 GRU 的序列编码器,它有重置门 (reset gate) 和更新门 (update gate),两个门一起决定有多少信息要更新。
首先将词转化为词向量,再通过双向 GRU ,把结果 concat 在一起得到词的表示:
$$x_{it} = W_ew_{it}$$ $$\overrightarrow{h_{it}} = \overrightarrow{GRU}(x_{it})$$ $$\overleftarrow{h_{it}} = \overleftarrow{GRU}(x_{it})$$ $$h_{it} = [\overrightarrow{h_{it}}, \overleftarrow{h_{it}}]$$
attention 机制是要找到句子中对含义贡献最大的词,$u_{it}$ 为 $h_{it}$ 的隐含表示:
$$u_{it} = tanh(W_wh_{it} + b_w)$$ $$\alpha_{it} = \frac{exp(u_{it}^Tu_w)}{\sum_texp(u_{it}^Tu_w)}$$ $$s_i = \sum_t\alpha_{it}h_{it}$$
$u_w$ 为随机初始化的上下文向量,$\alpha_{it}$ 为 attenttion 的权重矩阵,表示第 i 个句子的第 j 个词。$s_i$ 为下一层的输入。句子级别和文档级别的表示与词类似。
实践经验
模型选择
学术和工程实践的 Gap 往往很大,学术考虑模型的设计,实践中还要考虑效率、性价比等等。实践中往往先用 CNN 做到比较好的结果再来改进模型,由于 RNN 提升的不是特别明显,但是训练开销巨大,在限时赛中经常使用 CNN 及其改进模型。
防止过拟合
除了常用的方法,值得一提的是 dropout 往往很有效,默认的参数0.5在很多情况下效果不错。如果数据集很小或者用了更好的方法,比如 batch norm,可以不用 dropout。
关注每一次迭代
善用 tensorboard, visdom 等可视化工具,关注每一次迭代的质量。必要的时候可以手动调整每个 epoch 的 batch_size, optimizer, lr 等参数。
数据处理
词向量的 fine-tuning 很重要。迭代时默认开启 shuffle。
超参数调节
上文提到的 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification 详细的介绍了超参数调节的实验过程,可以参考这篇文章。
组合激活函数
每一种激活函数都会丧失一部分信息,可以把不同的激活函数 concat 起来,通过梯度自动选择适合的激活函数。
类别不均衡
- 欠采样:丢弃一些反例,使得正、反例数目接近。
- 过采样:增加一些正例,使得正、反例数目接近,即数据增强。
- 阈值移动:$m^+$, $m^-$ 分别为正、反例数目,$y$ 为正例的可能性,通常认为若 $\frac{y}{1-y} > 1$,即 $y > 0.5$ 时预测为正例,其中 0.5 即为阈值。类别不均衡时,$\frac{y}{1-y} > \frac{m^+}{m^-}$ 时才预测为正例,可以看出正、反例 1:1 时阈值为 0.5 才是合理的。
实现参考
brightmart/text_classification 这里有文本分类深度学习方法全套合集。
参考
- Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
- Multi-Task Label Embedding for Text Classification
- Bag of Tricks for Efficient Text Classification
- Convolutional Neural Networks for Sentence Classification
- A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
- A Convolutional Neural Network for Modelling Sentences
- Recurrent Neural Network for Text Classification with Multi-Task Learning
- Recurrent Convolutional Neural Networks for Text Classification
- Hierarchical Attention Networks for Document Classification
- Neural Machine Translation by Jointly Learning to Align and Translate
- Attention Is All You Need
- Ask Me Anything: Dynamic Memory Networks for Natural Language Processing