RL:from value to policy
前一段时间看了ti8,对OpenAI的实现还是很感兴趣的,以前大概也就看到DQN,后面的就没怎么看了,这次再捡起来,沿着Value-Based,Policy-Based,到Actor-Critic结构的很多(结合value和Policy).本文的梳理顺序是Sarsa,Q-Learning,DQN,Policy-Gradients,Actor-Critic,DDPG,A3C,PPO.
Backgroound
这里需要先解释几个名词:
- State(S) 状态
- Reward(R) 回报
- Action(A) 行动
- Environment(E) 环境
- Value(V) 值
- Q Q值
- $\pi$ 策略
然后还需要解释几个相关的概念:
one-step VS n-step
$$V(s_0) = r_0 +\gamma r_0$$
$$V(s_0) = r_0 +\gamma r_0 + \cdots + \gamma^nr_n$$
这个根据名字和公式就能看出来,one-step是每次只向后考虑一步,而n-step是每次向后考虑n步.
$\epsilon$ - greedy (exploit VS explore)
这个又涉及到一个老生常谈的话题,就是探索和利用之间的矛盾,也就在当前情况下,我是选择最好的策略,还是选择去尝试没有试过的东西.一般都是以0.9的概率进行贪婪,0.1的概率进行随机(探索).即一般将这个$\epsilon$设置为0.1.
on-policy VS off-policy
这个是在线学习还是离线学习,只在线学习就是相当于以串行的方式一直接受着数据,学习时利用当前策略进行更新;而离线学习就是利用已经有的数据,进行学习(就像图片识别那样),学习的时候并不是利用当前策略进行更新的.其实在这里,我相信屏幕前的你肯定不懂,但是没关系,这部分在讲到Sarsa和Q-Learning的时候会进行更加详细的说明.
Value-Based
下面正式进入正题,是关于value-based的方法,也就是基于价值的强化学习算法,这部分算法是以一个Q值来衡量好坏,也就是对一个State下的所有的Action拿到Q值,然后根据Q值来进行衡量使用哪个Action.因为要维护一个Q值的表,所以只适合少量的并且是离散的情况.典型的算法有Sarsa,Q-Learning,DQN等等.后面会详细叙述.
Policy-Based
这个基于策略的方法是直接根据State得到Action,也就是我们直接根据策略选择Action,而不是Q值.基于策略的适合高维连续,适用性更加广泛一些.
经典算法
Sarsa and Q-Learning
这里就涉及到了前面的on-Policy和off-Policy了,前面没有例子,不好解释,这里刚好拿这两个算法来举例子,其中Sarsa为on-Policy的,而Q-Learning刚好为off-Policy的.下面贴一张在stackoverflow上面的图,问题的链接在这里,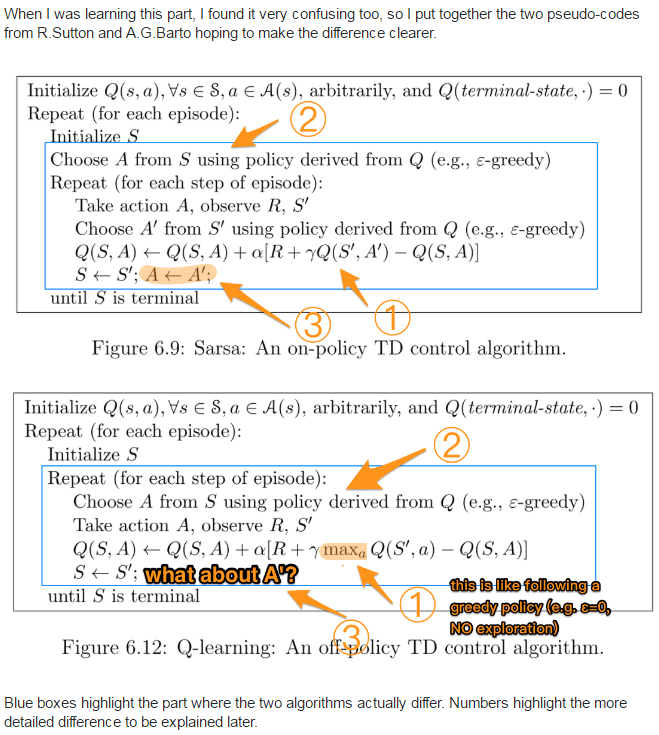
从这张图可以看出,采用的方法就是初始化状态和策略,也就是我们的Q值表,即这里所谓的策略,就是我们根据Q值表进行选择相应Action.然后不断地根据reward更新我们的Q值.而他们的区别就在更新Q值的时候使用的是和前面拿到Action一样的策略,还是用的另一个策略,从上面的图中就可以看到,Sarsa的里面更新Q用的是和上面一样的策略,但是Q-Learning则不同,这里用的是Q表中在这个状态的采取所有行动最大的Q值.
DQN
当问题变的复杂的时候,Q-Learning就会有一个问题,那就是这个Q表会变得非常复杂,因为这个表相当于是一个$S \cdot A$的表,会变得十分的庞大,当遇到连续的问题的时候,就会变得复杂到没有办法解决,就需要的到策略梯度了,不过这个是后面的东西,当面对复杂的离散问题的时候,比如围棋这种,我们就可以使用DQN来解决,DQN,从名字就应该知道使用了深度学习的东西,具体的话,其实就是将Q表使用神经网络来替换,也就是我们输入S和A,输出Q值,就可以了.原理就是这么简单.
(tips: 我们在这里面并不是像cv那样很强调网络的结构,这里一般都是很简单的几层的网络,因为网络在RL里面的作用是map一个函数,所以这里和后面的介绍中,都不会介绍具体的网络结构,如果需要的话可以查看相关的论文和实现.)
理解起来简单,但是在实现中,还是会有一些问题,比如前面我们是直接进行更新Q值的,但是现在不一样了,我们现在是神经网络,需要有loss函数,等等.我们先来看一下这个loss如何定义.回过头看Q-Learning的Q值的更新方式.
$$Q^\ast(s,a)=Q(s,a)+\alpha(r+\gamma\max_{a^\prime}Q(s^\prime,a^\prime)-Q(s,a))$$
这个公式的意思就是新的Q值等于原来的Q加上$\alpha$倍的(回报r,加上下一个状态的最大的Q值,减去原来的Q值),在思考一下,其实就是将我们的Q值,向
$$r+\gamma\max_{a^\prime}Q(s^\prime,a^\prime)$$
迈进$\alpha$.根据这个理论,我们就可以很容易的得到DQN的loss的计算方式,也就是下面的.
$$L(\theta)= E[(TargetQ-Q(s,a;\theta)^2)]$$
$$TargetQ =r+\gamma \max_{a’}Q(s^\prime,a^\prime;\theta)$$
和上面的一样,都是要输出的Q值去接近target.
现在我们已经解决了关于loss的问题,显然DQN也是一个off-policy的方法,那么我们就可以在本地学习$<s,a,r,a^\prime>$这样的数据集了,也就是我们有我们的memery池了.
最后还有一个问题,什么问题呢?在训练的时候DQN十分的不稳定,原因很简单,因为我们在target里面用的Q和Loss里面的Q是同一个Q,想象一下,某些参赛选手当裁判,那裁判的判定标准肯定是根据他自己在哪方面擅长而变化,评判的标准就变得很不稳定.解决这个问题的方法也很简单,只需要再加一个网络就可以了,并且在训练的时候,隔很多步再把其中一个网络的参数同步过去,这样就保证了在很多步内是稳定的.
DQN的部分就到这里结束了,同时也应该看到DQN也存在很多的问题,首先就是最大的问题,连续值,也就是当Action并不是离散的时候,是没有办法用的,同样的,更大的问题规模同样可以使DQN不起作用.解决这个问题的办法就是下面要讲的PG.
Policy Gradients
PG的思想其实很简单,回忆前面的DQN,其中神经网络的作用是输入状态S和行为A,之后得到的是Q值,之后根据Q值来决定行为,那我们为什么我们不直接将S输入,得到A呢?根据S选择A,这本质就是一个策略,而这个深经网络可以使用梯度下降来进行优化,所以的得名PG.(这里不是直接输出A,而是A的一个概率分布)和上面同样的道理,我们要设计我们的Loss函数,还有梯度的计算.我们这里需要先明确一个目标,我们的策略的终极目标是使我们最后拿到的回报的期望最大,这里我们可以先拿$f(x)$表示成最终的目标,那么我们对它的期望求梯度,就变成了这个样子$\nabla_\theta E[f(x)]$,接下来可以看下面的推到了
这里面比较难理解的是倒数第二行这里的推到,这里看后面的注释就很容易理解了,将其中的$z$换成$p(x)$再把公式倒过来,就成了倒数第三行到倒数第二行的情况了.这样我们就得到了策略梯度的推到过程,再将其中的一些符号使用我们在强化学习中常用的符号代替,就得到了下面的公式
$$\nabla_{\theta}J(\pi)=E_{s\sim\rho,a\sim\pi(s)}[A(s,a) \cdot\nabla_\theta\log\pi(a|s)]$$
这里的$A(s,a)$就是上面的$f(x)$,后面的一项也是这样.关于这个公式的理解,也非常有趣,这个公式有两项第一项是$A(s,a)$一个标量,代表着趋势,(或者可以说是个reward,但也不确切是,会面会讲到这一点)也就是后面的这个梯度是朝着好的方向发展还是朝着坏的方向发展,后面的一项就是这个策略的梯度的方向,总结起来就是回报越高的动作最后的概率也就越大.打个比方这局围棋赢了,那么我可以定义我的$f(x)$为1,如果输了就为-1,但是这样的话每局有好多步,每一步都是1或者都是-1显然是不对的,能不能在每一步都计算这个$A(s,a)$呢?下面的就解决了这个问题.
Actor-Critic
顾名思义,行动者-评论家,看起来很像CV里面的Gan.但是从RL的角度,这个模式是将基于策略和基于值结合在了一起,由Actor来做基于策略的部分,而Critic来做基于值的部分,Actor所做的是输入S,输出A,Critic做的是输入S和A,输出Value.而这个value就可以是前面的PG的$A(s,a)$,当然这个$A(s,a)$并没有这么简单,他其实是这样求的
$$A(s,a) = Q(s,a)-V(s)$$
这个式子代表着一个优势,这个优势就是在s采取a到底有多优,也就等于s状态下采取a的value减去s的value.拿着个A去替换上面的式子里面的A,就得到了A-C的公式了.
DDPG
DDPG也使用了A-C的模式,同时又融入了DQN的东西,比如使用一个新的网络,缓慢的移动到新的网络(DQN是隔几步再切换过去)等等,我们这里直接看算法的详细步骤.
首先我们初始化我们的Q和$\mu$网络,之后呢,我们还有targetQ和$target\mu$网络,初始化的时候参数是一样的.之后准备buffer,用来replay,初始化状态s1.之后开始循环,首先根据$\mu$和噪声得到a,这里的噪声,其实就相当于在Background中介绍的$\epsilon$-gredey原则,用来平衡exploit和explore.之后在环境中执行a,得到r和$s_{t+1}$,之后将这个对存储起来$<s_t,a_t,r_t,s_{t+1}>$.接下来就可以minibatch了,从存储的里面取出一个batch,时候就比较复杂了,首先计算了critic的loss,这里我们可以把上面的DQN的loss搬过来对比一下
$$L(\theta)= E[(TargetQ-Q(s,a;\theta)^2)]$$
$$TargetQ =r+\gamma \max_{a^\prime}Q(s^\prime,a^\prime;\theta)$$
这里使用了求和除以N(batch_size),就相当于求期望,这里的$y_i$就是上面的$TangetQ$,这样解释就能够看懂了.然后是后面的Actor的梯度,我们同样也是回顾一下前面PG的公式
$$\nabla_\theta J(\pi)=E_ {s\sim\rho,a\sim\pi(s)}[A(s,a) \cdot\nabla_\theta \log\pi(a|s)]$$
这里也是求和除以N,是求期望,然后就像A-C里面那样,使用Q来代替A,后面就是梯度.是一样的.最后再看更新方式,这里使用了DQN的双网络的方法,不过不是隔几步参数平移过去,是每次都靠近一点.
A3C
A3C就是3个A-C,因为A-C会出现一些问题,最重要的问题就是关于相关性的,在一次的迭代当中s的相关性会比较高,这个时候需需要解决这个问题,我们可以使用并行来解决这个问题,也就是我们可以同时进行三个A-C,然后同时学习,这样效率提高了,相关性的问题也解决了.(PS:详细的我还没看,只是讲了大概的原理,这里先占个坑)
PPO
(PS:同上,先占个坑)
PPO解决的是优化不长的问题,步长大了会不稳定,步长小了又太慢.所以他们想到使用一个公式来限制步长
$$L^{CLIP(\theta)}=\hat{E_t}[min(r_t(\theta)\hat{A_t},clip(r_t(\theta),1-\epsilon,1+\epsilon)\hat{A_t}) ]$$
其中
$$r_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_old}(a_t|s_t)}$$
也就是将更新的比值限制在了$(1-\epsilon,1+\epsilon)$,通过这个方式来保证相对合理的步长.
总结
这次的博客总结了很长时间,其中的公式都是手打的,真的是太难受了.不过收获还是很大的,算是从value和policy的角度理清了RL的一个脉络.还有就是一直看CV的东西,好久没有看过这么复杂的公式了,也算是提高一下数学能力吧.