从StarGAN到GAN
最先接触的是StarGAN,看到不懂就向下看论文解决依赖,于是就有了这篇写时“自顶向下”,读时“自底向上”的文章。
1、GAN(Generative Adversarial Net)
GAN,即生成对抗网络,出现的目的是解决自动生成问题,在图像领域已经有了很大成果。GAN的原理是有两个网络G和D。分别代表生成(generator)和判断(Discriminator)。同时训练这两个网络:
1、对于G,训练其画出更高质量的图像;
2、对于D,训练其有更强的判断能力;
我们期待的最后结果是,G生成的图像在D眼中质量真假难辩(50%)。
1.1、Value Function
GAN并没有损失函数,优化的过程是G与D之间的“零和博弈”:
$$min_{G}max_{D}V(D,G)=E_{x~p_{data}(x)}[logD(x)]+E_{z~p_{z}(z)}[log(1-D(G(z)))]$$
训练过程中D需要尽可能地正确分类,即最大化$E_{x~p_{data}(x)}[logD(x)]$;相应地G需要最大化D的损失,即最小化$E_{z~p_{z}(z)}[log(1-D(G(z)))$。训练中依次更新D和G的参数进行j交替迭代:
每次按照分布$P_{g}(z)$取minibatch:${z^{(1)},…,z^{(m)}}$进行训练,
D的随机梯度下降:$\nabla_{\theta d} \frac{1}{m}\sum_{i=1}^{m}[log(D(x^{(i)})+log(1-D(G(z^{(i)})))]$
G的随机梯度下降:$\nabla_{\theta g}\frac{1}{m}\sum_{i=1}^{m}log(1-D(G(z^{(i)})))$
1.2、优缺点
优点:OpenAI Ian Goodfellow的Quora问答:高歌猛进的机器学习人生
1、生成的样本质量更高;
2、生成对抗式网络框架能训练任何一种生成器网络(理论上-实践中,用 REINFORCE
来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero
mass)。生成对抗式网络能学习可以仅在与数据接近的细流形(thin manifold)上生成点;
3、不需要遵循任何种类的因式分解模型,任何G和D都是通用的;
缺点:
1、GAN在“纳什均衡”下达到最优,但是非凸优化可能不能靠梯度下降收敛到最优,训练没有终点;
2、过于自由,G和D缺少限制,无法区分训练过程中是否有进展;
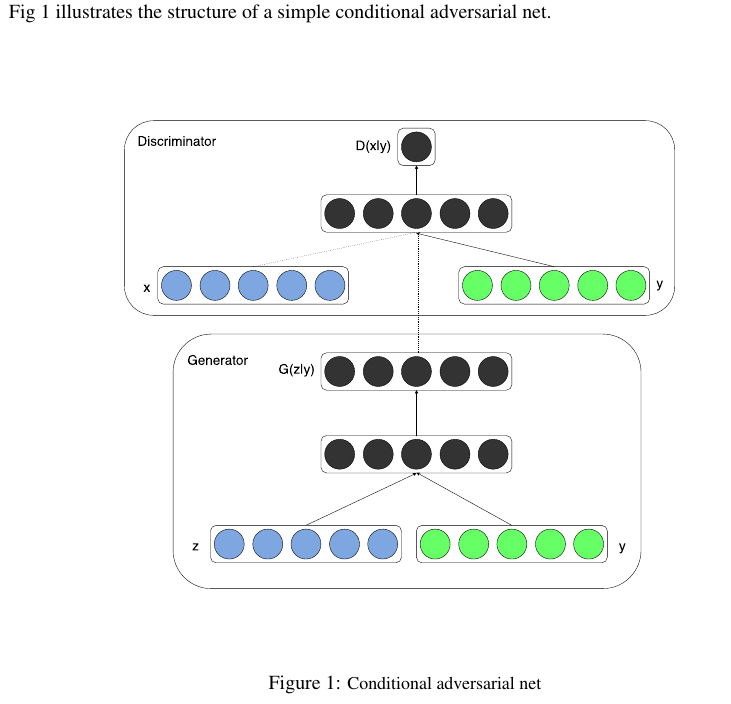
2、cGAN(Conditional Generative Adversarial Nets)
与GAN相比,有了最简单的条件控制。
2.1、Value Function
GAN的value function:
$$min_{G}max_{D}V(D,G)=E_{x~p_{data}(x)}[logD(x)]+E_{z~p_{z}(z)}[log(1-D(G(z)))]$$
cGAN的value function:
$$min_{G}max_{D}V(D,G)=E_{x~p_{data}(x|y)}[logD(x)]+E_{z~p_{z}(z)}[log(1-D(G(z|y)))]$$
区别在于条件变量y的引入,其作为一个额外的输入层。y可以是任何辅助数据,比如类标签。
作者后面使用了mnist数据集,将类别的one-hot标签和100维的噪声输入。
3、Pix2Pix
Pix2Pix算法对图像翻译(Image-to-image Translation)有很大贡献,把图像到图像的翻译用同一个过程来表示,比如风格迁移。会用到成对数据集,分别代表迁移domain和被迁移domain,GAN会学习这种映射关系。
3.1、设计
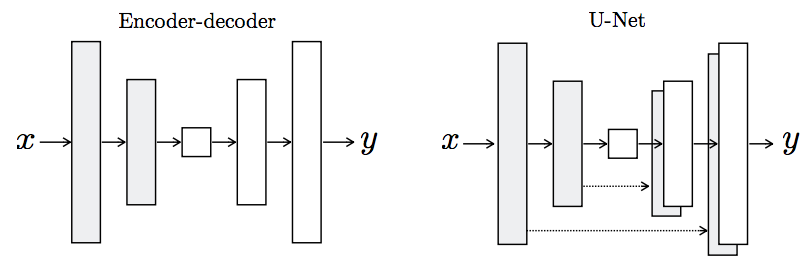
3.1.1、G with U-net
G输入由随机噪声变为一张图片,输出也是一张图片。其中G使用了U-net的结构,这种结构利用了之前feature map等大时的信息,可以防止特征在压缩的过程中流失。
3.1.2、D with Patch
已知L1/L2可以给图像生成带来模糊影响,在低频率清晰度表现不错,但是不鼓励高频清晰度(high-frequency crispness)。为了模拟高频率可以采取关注局部的策略。
使用将图片分成若干个Patch(N*N),并训练一个相应大小的D对其判断真假,平均所有的响应来得到输出。
优点在于:
1、小的PatchGAN参数更少便于训练;
2、G是全卷积,D使用了Patch分割,都不要求大小,可以直接用于更大的图像。
3.2、损失函数
对抗损失
$$L_{cGAN}(G,D)=E_{x~p_{data}(x|y)}[logD(x)]+E_{z~p_{z}(z)}[log(1-D(G(z|y)))]$$
同时训练一个普通GAN,判断是否为真实图像
$$L_{GAN}(G,D)=E_{x~p_{data}(x)}[logD(x)]+E_{z~p_{z}(z)}[log(1-D(G(z)))]$$
使用L1正则项而不使用L2
$$L_{L1}(G)=E_{x,y,z}[||y-G(x,z)||_{1}]$$
总损失函数如下
$$L_{cGAN}(G,D)+\lambda L_{L1}(G)$$
$$G^{*}=argmin_{G}max_{D}L_{cGAN}(G,D)+\lambda L_{L1}(G)$$
3.3、训练特点
使用GAN标准的G/D交替优化方式,使用minibatch SGD并应用Adam算法。
inference与常规不同,在测试时使用与训练时完全相同的dropout。
此外inference使用批量归一化的测试数据而不是训练数据。
4.3、实验
4.3.1、loss实验
实验中使用了cGAN、L1、cGAN+L1,结果如下:

可以看到只使用cGAN会得到过多的东西,这里L1正则化的作用是适度模糊化,加上之后效果好了很多。
4.3.2、incoder-decoder/U-net实验
比较两者,明显使用U-net有效保护并保留了重要信息,使得生成的图像真实了很多。

4.3.3、Patch实验
使用不同大小的patch进行实验:

大小为1就是Pixel的D,除了提供更多的颜色没有别的优势,大小16已经比较清晰但是细节还是不太好,大小70强制锐化(sharp)即使不太正确,之后就没有什么显著提升。
4.3.4、color实验
图中表示的是色彩的分布:
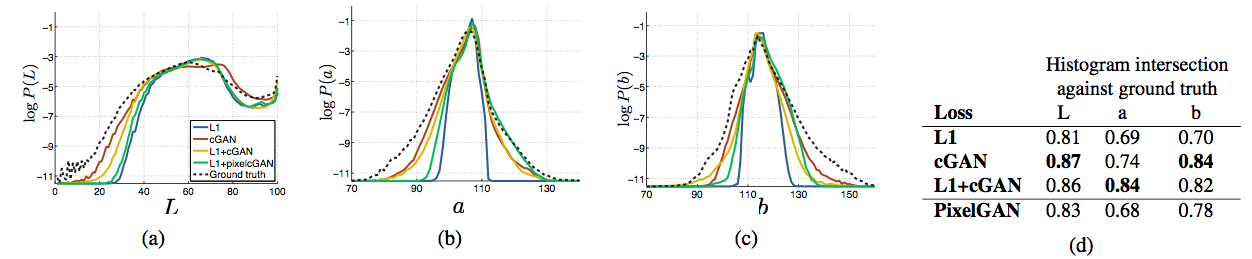
由色彩分布的宽度可以看出cGAN促进生成色彩鲜艳的成分,而L1起到了淡化、灰度化作用,与上面的结果符合。
4、CircleGAN
Pix2Pix算法需要使用成对图像,如下:
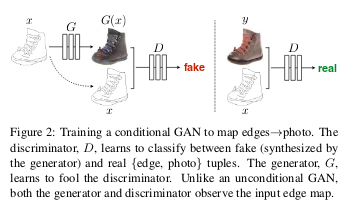
要实现风格迁移之类的任务,通常需要包含成对图片的训练集合来让GAN学会映射关系。
但是实际情况是并没有足够的成对图片给我们学习这种映射关系,CircleGAN保证对不成对的数据集也能学习图像迁移(Image-to-image Translation)的方法。
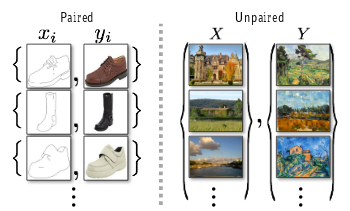
那么要如何在学习不知道目标的情况下的迁移方法呢?
4.1、设计
这个GAN含有两个函数$G:X \rightarrow Y$和$F:Y \rightarrow X $,就像是一个环,同时学习映射和反向映射,相应的D的判别结果则分别表示为$D_{Y}$和$D_{X}$,前者鼓励G的正确性,后者鼓励F。
4.1.2、Circle Consistency,循环一致性
循环一致性分为前向和后向:
1、前向循环一致性:$X\rightarrow G(X)\rightarrow F(G(X))\approx X$
2、后向循环一致性:$Y\rightarrow F(Y)\rightarrow G(F(Y))\approx Y$
这个前提保证了我们在数据集不成对的情况下也能训练出正确的G。
4.2、损失函数
4.2.1、Adversarial Loss,对抗损失
对于$G:X \rightarrow Y$和其判别网络$D_{y}$
$$L_{GAN}(G,D_{Y},X,Y)=E_{y~P_{data}(y)}[logD_{y}(y)]+E_{x~P_{data}(x)}[log(1-D-{y}(G(x)))]$$
训练目标即为:
$$min_{G}max_{D_{Y}}L_{GAN}(G,D_{Y},X,Y)$$
同理我们也有:
$min_{F}max_{D_{x}}L_{GAN}(G,D_{X},Y,X)$
4.2.2、Circle Consistency Loss,循环一致损失
若数据集足够大,网络可以把输入随机映射到对面之外的地方去,另一侧学习的任何映射都可以与之相匹配;所以单独的对抗损失是不能保证正确的G和F的,需要利用循环一致性约束。
所以进一步减少映射空间,利用循环一致性:
$$L_{cyc}(G,F)=E_{y~P_{data}(y)}[||F(G(x)-x||_{1}]+E_{x~P_{data}(x)}[||G(F(y))-y||_{1}]$$
这代替了L1损失。
4.2.3、完整的损失函数
$$L(G,F,D_{x},D_{y})=L_{GAN}(G,D_{Y},X,Y)+L_{GAN}(F,D_{X},Y,X)+\lambda L_{cyc}(G,F)$$
$$G^{},F^{}=argmin_{G,F}max_{D_{X},D_{Y}}L(G,F,D_{x},D_{y})$$
可以理解为这个GAN是在训练两个自编码器,整个训练过程是“对抗性自编码器的训练”。
4.3、比较
4.3.1、与其他GAN的比较
与CoGAN、SimGAN、Feature loss + GAN、BiGAN/ALI、pix2pix进行了比较,结果都表明CircleGAN的表现更好。
4.3.2、CircleGAN各成分的重要性
实验中分离原始GAN、Cycle、前向Circle、后向Circle来分析各个成分的作用:
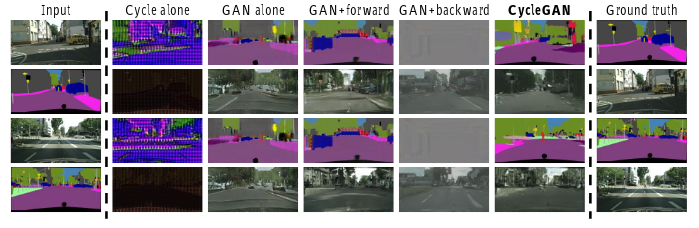
其中前向循环一致似乎比后向循环一致性更重要。
5、StarGAN
StarGAN提供了一个多领域图像迁移(multi-domain image-to-image translation)的统一模型。
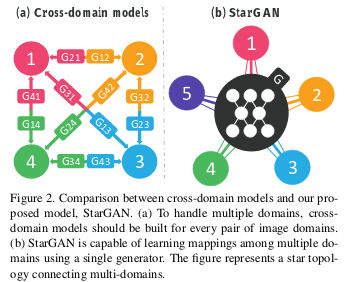
针对多领域图像迁移,旧模型的策略是k个domain,就需要学习k(k-1)个G。这么做的缺点很明显:
(1)这样的每个生成器都没有利用整个数据集,生成的图片可能会很低效;
(2)无法联合来自不同dataset的domain,因为每个dataset都是部分标记的。
5.1、设计
StarGAN给出了下面的结构:
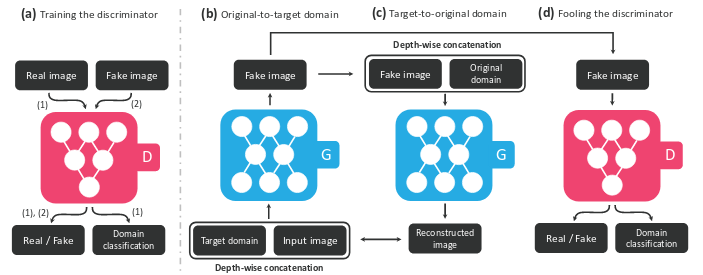
G除了输入origin域的图像还要给出一个target域的标签,之后利用CircleGAN中的循环一致性来保证图片的信息没有在迁移过程中丢失;
D能够判断图像属于哪个类别。
5.2、损失函数
5.2.1、Adversarial Loss,对抗损失
$$L_{adv}=E_{x}[logD_{source}(x)]+E_{x,c}[log(1-D_{source}(G(x,c)))]$$,(1)
5.2.2、Domain Classification Loss,域分类损失
将域分类损失分为两部分,一部分是优化D的真实图像的损失,一部分是优化G的假图像的损失:
真图像部分为:
$$L_{cls}^{r}=E_{x,c}[-logD_{cls}(c’|x)]$$,(2)
其中$$D_{labels}(c’|x)$$是由D计算出的c的分布,通过最小化损失D学会真实图像x对应的domain。
假图像部分为:
$$L_{cls}^{f}=E_{x,c}[-logD_{cls}(c|G(x,c))]$$,(3)
通过最小化来生成可分类为c的图像。
Domain Classification Loss,域分类损失
将域分类损失分为两部分,一部分是优化D的真实图像的损失,一部分是优化G的假图像的损失:
真图像部分为:
$$L_{cls}^{r}=E_{x,c}[-logD_{cls}(c’|x)]$$,(2)
其中$$D_{labels}(c’|x)$$是由D计算出的c的分布,通过最小化损失D学会真实图像x对应的domain。
假图像部分为:
$$L_{cls}^{f}=E_{x,c}[-logD_{cls}(c|G(x,c))]$$,(3)
通过最小化来生成可分类为c的图像。
5.2.3、Reconstruction Loss,重构损失
$$L_{rec}=E_{x,c,c’}[||x-G(G(x,c),c’)||_{1}]$$,(4)
最小化对抗损失和分类损失的过程中,G被训练为生成和目标域更接近的图像。但是最小化不能保证翻译的图像保留输入图像的内容,并且只改变输入和域相关的部分。为了解决这个问题使用CircleGAN的循环一致损失函数。
G接受的c’是origin domain的标签,试图重构图片x。
5.2.4、完整的损失函数
$$L_{D}=-L_{adv}+\lambda_{cls}L_{cls}^{r}$$,(5)
$$L_{G}=L_{adv}+\lambda_{cls}L_{cls}^{f}+\lambda_{rec}L_{rec}$$,(6)
5.3、多数据集训练
训练过程如下图所示。
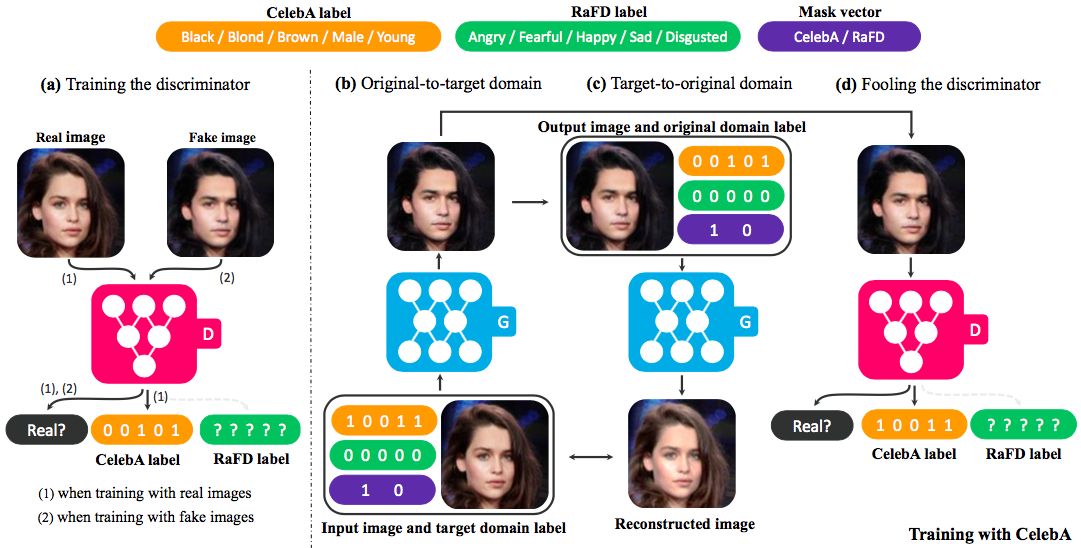
在重构输入的过程中我们需要原图片的完整信息c’,使用下面这种方法构建。
5.3.1、Mask Vector,掩码向量
掩码矢量允许StarGAN忽略未指定的标签,专注于已指定的标签。使用n维one-hot向量表示m,n表示数据集的数量,将标签的统一版本定义为
$$c’=[c_{1},c_{2},…,c_{n},m]$$
其中$$c_{i}$$就表示第i个数据集的标签,其余n-1个标签不知道就直接赋值为0。如作者的实验中有CelebA和RaFD两个数据集,所以其n=2。
5.3.2、Training Startegy
我们使用上面的c作为域标签输入,这么做使得G学会忽略未指定的标签,而且现在G的结构和面对一个数据集是一样的。比如:当使用CelebA中的图像进行训练时,D仅最小化与CelebA属性相关的标签的分类错误,而不是与RaFD相关的面部表情。